위 글은 해당 카테고리의 수업 강의 자료를 정리한 것입니다.
1. 그룹 함수 JOIN
1.1 그룹 함수의 특징
- 여러 행으로부터 하나의 결과 값을 반환
- 집계 함수, 그룹 함수, 복수행 함수
- 종류
- avg(): 평균 값 반환
- count(): 총 건 수 반환
- count(*)
- count(컬럼명)
- max(): 최대값 반환
- min(): 최소값 반횐
- sum(): 합계 반환
- 그룹 함수의 결과는 한 row만 남게 됨
- department_id는 하나의 row에 표현할 수 없음
- 부서별로 연봉 평균이 필요한 경우 GROUP BY절 사용

1.2 그룹 함수 count()
- 함수에 입력되는 데이터의 총 건수를 구하는 함수
select count(*), count(commission_pct)
from employees;대상 건수에 null이 있다면 count되지 않음
1.3 그룹 함수 sum()
- 입력된 데이터들의 합계 값을 구하는 함수
select count(*), sum(salary)
from employees;
1.4 그룹 함수 avg()
- 입력된 값들의 평균 값을 구하는 함수
- null 값이 있는 경우 빼고 계산 (NVL() 함수와 같이 사용)
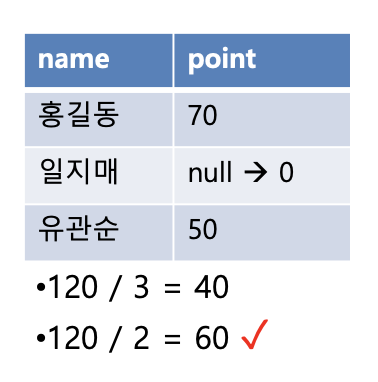
select count(*), sum(salary), avg(salary)
from employees;select count(*), sum(salary), avg(nvl(salary,0))
from employees;
2. GROUP BY 절

2.1 GROUP BY 절에서 자주하는 오류
- GROUP BY에 참여한 컬럼이나 그룹 함수만 (SELECT에) 올 수 있음
예시1 ⭕️
select department_id, count(*), sum(salary)
from employees
group by department_id;예시2 ❌
select department_id, job_id, count(*), sum(salary)
from employees
group by department_id;예시3 ⭕️
select department_id, job_id, count(*), sum(salary)
from employees
group by department_id, job_id;
- WHERE절에는 그룹함수를 쓸 수 없음
예시 ❌
select department_id, count(*), sum(salary)
from employees
where sum(salary) > 20000
group by department_id;
3. HAVING 절
- HAVING절에는 그룹함수와 GROUP BY에 참여한 컬럼만 사용할 수 있음
예시1
select department_id, count(*), sum(salary)
from employees
group by department_id
having sum(salary) > 20000;
예시2
select department_id, count(*), sum(salary)
from employees
group by department_id
having sum(salary) > 20000 and department_id = 100;
3.1 GROUP BY ~ HAVING 절

4. CASE ~ END문 / DECODE() 함수
4.1 CASE ~ END문
- if else문과 유사
CASE WHEN 조건 THEN 출력1
WHEN 조건 THEN 출력2
...
ELSE 출력3
END "칼럼 Alias"
예시
SELECT employee_id, salary,
CASE WHEN job_id = 'AC_ACCOUNT' THEN salary + salary * 0.1
WHEN job_id = 'AC_MGR' THEN salary + salary *0.2
ELSE salary
END job_id
FROM employees;
5. JOIN
- 직원의 이름과 직원이 속한 부서명을 함께 보고 싶다면
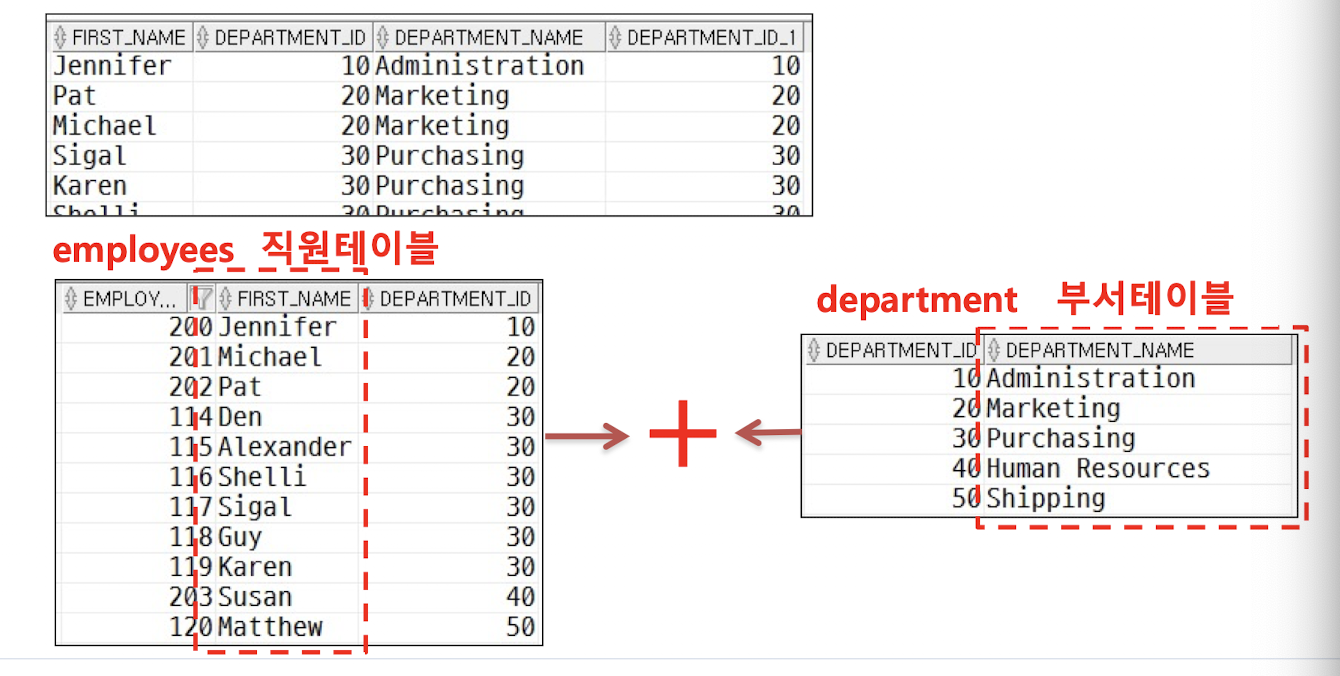
- 둘 이상의 테이블을 합쳐서 하나의 큰 테이블로 만드는 방법
- 관계형 모델에서는 데이터의 일관성이나 효율을 위하여 데이터의 중복을 최소화 (정규화)
- Foreign Key를 이용하여 참조
- 정규화된 테이블로부터 결합된 형태의 정보를 추출할 필요가 있음
- 예시: 직원의 이름과 직원이 속한 부서명을 함께 보고 싶다...
- 두 테이블에서 그냥 결과를 선택하면?
select first_name, department_name
from employees, departments;
- 결과: 두 테이블의 행들의 가능한 모든 쌍이 추출됨
- 일반적으로 사용자가 원하는 결과가 아님 (107*27 = 2889건)
- 이때 카디션 프로덕트(Cartesian Product)를 진행하여 올바른 조인 조건을 WHERE절에 부여해야 함
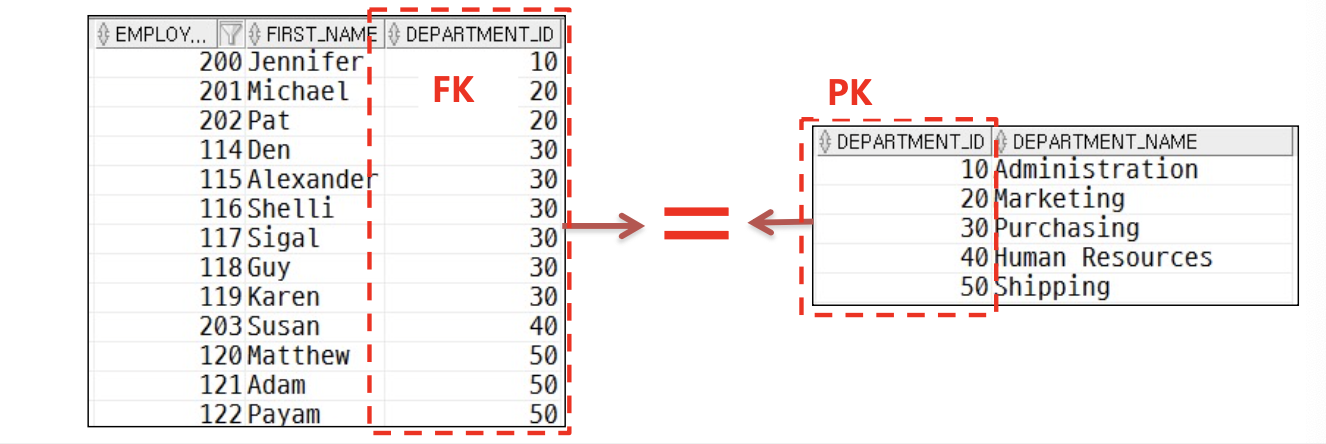
- EQUI JOIN
select first_name, em.department_id, department_name, de.department_id
form employees em, department de
where em.department_id = de.department_id;
양쪽 다 만족하는 경우에만 조인 됨 (null 값은 조인 안됨)
- JOIN 설명
- FROM 절에 필요로 하는 테이블을 모두 적음
- 컬럼 이름의 모호성을 피하기 위해 (어느 테이블에 속하는지 알 수 없음)이 있을 수 있으므로 Table 이름에 Alias 사용 (테이블 이름으로 직접 지칭 가능)
- 적절한 JOIN 조건을 WHERE 절에 부여 (일반적으로 테이블 개수 -1개의 조인 조건이 필요)
- 일반적으로 PK와 FK간의 = 조건이 붙는 경우가 많음
select first_name, em.department_id, department_name, de.department_id
form employees em, department de
where em.department_id = de.department_id;
- JOIN 처리 방법

예시: 사원 이름과 그 사원의 매니저 이름 조회하기


select emp.first_name, mgr.first_name
from employees emp, employees mgr
where emp.manager_id = mgr.employee_id;
- OUTER JOIN
- JOIN 조건을 만족하지 않는 컬럼이 없는 경우 null을 포함하여 결과를 생성
- 모든 행이 결과 테이블에 참여
- null이 올 수 있는 쪽 조건에 (+)을 붙임
- 종류
- LEFT OUTER JOIN: 왼쪽의 모든 튜플은 결과 테이블에 나타남
- RIGHT OUTER JOIN: 오른쪽의 모든 튜플은 결과 테이블에 나타남
- FULL OUTER JOIN: 양쪽 모두 결과 테이블에 참여
- LEFT OUTER JOIN: 왼쪽 테이블의 모든 row를 결과 테이블에 나타냄
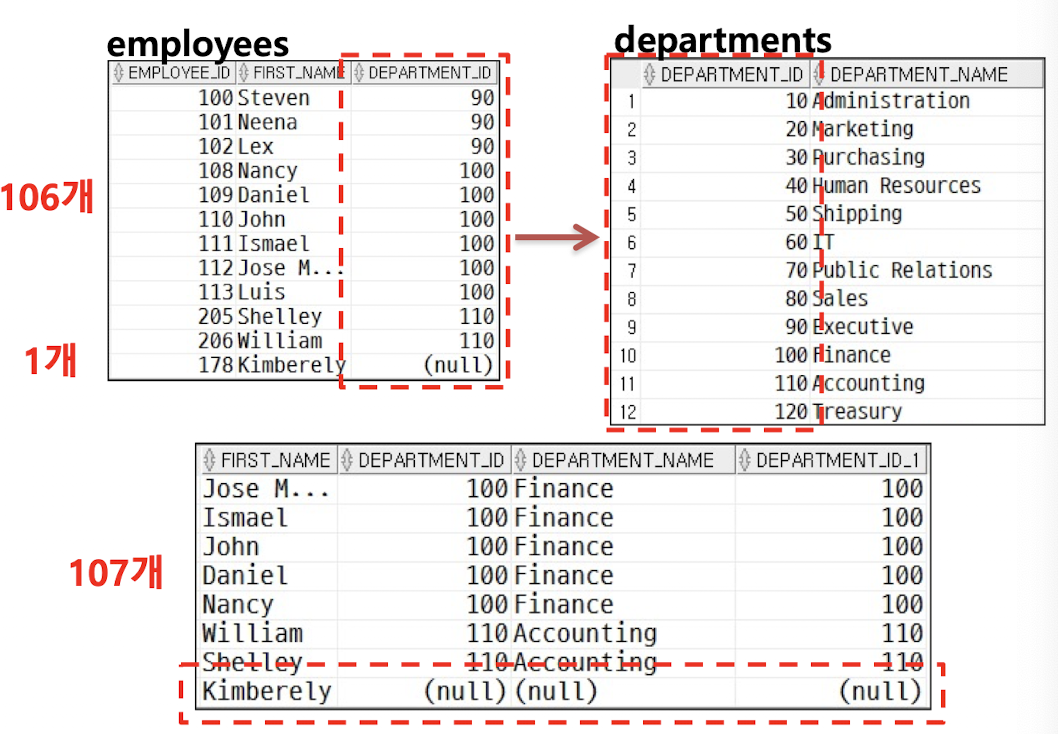
select e.department_id, e.first_name, d.department_name
from employees e left outer join departments d
on e.department_id = d.department_id;select e.department_id, e.first_name, d.department_name
from employees e, departments d
where e.department_id = d.department_id(+);
- RIGHT OUTER JOIN: 오른쪽 테이블의 모든 row를 결과 테이블에 나타냄

select e.department_id, e.first_name, d.department_name
from employees e right outer join departments d
on e.department_id = d.department_id;select e.department_id, e.first_name, d.department_name
from employees e, departments d
where e.department_id(+) = d.department_id;
- RIGHT OUTER JOIN ➡️ LEFT OUTER JOIN

- FULL OUTER JOIN
select e.department_id, e.first_name, d.department_name
from employees e full outer join departments d
on e.department_id = d.department_id;
- OUTER JOIN

- SELF JOIN
- 자기 자신과 조인
- Alias를 사용할 수 밖에 없음
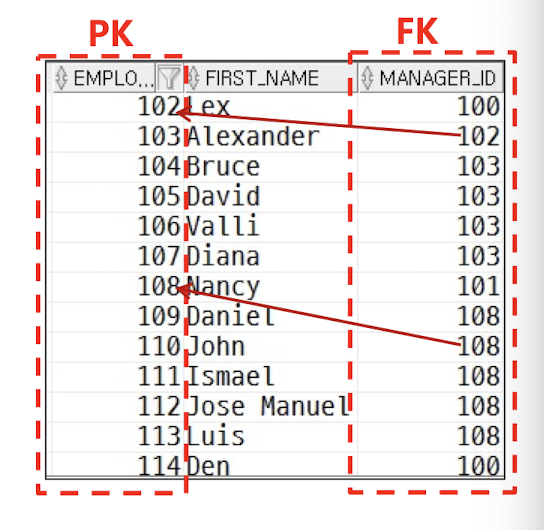
예시 1

select emp.employee_id, emp.first_name, emp_manager_id, man.first_name manager
from employees emp, employees man
where emp.manager_id = man.employee_id;
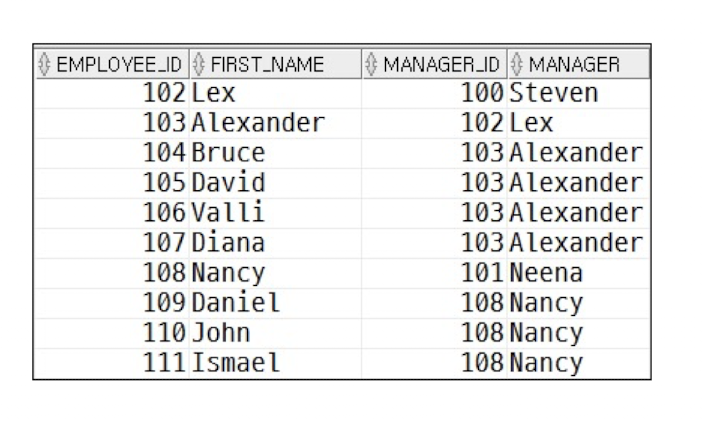
예시2

select emp.employee_id, emp.first_name, emp.manager_id, man.first_name manager
from employees emp, employees man
where emp.manager_id = man.employee_id;

'강의 > KOSTA' 카테고리의 다른 글
| [Oracle] DCL / DDL / DML (Day12) (0) | 2022.03.21 |
|---|---|
| [Oracle] SubQuery & rownum (Day12) (0) | 2022.03.21 |
| [Oracle] Basic Select Statements and Single-Row Functions (Day9) (0) | 2022.03.16 |
| [Oracle] Introduction to Database (Day9) (0) | 2022.03.16 |
| [Oracle] Installation Related Note(Day9) (0) | 2022.03.16 |